Last updated: February 19, 2026
5 min read
💤 Introduction: A False Job, A Real Problem
A few weeks ago, something strange happened.
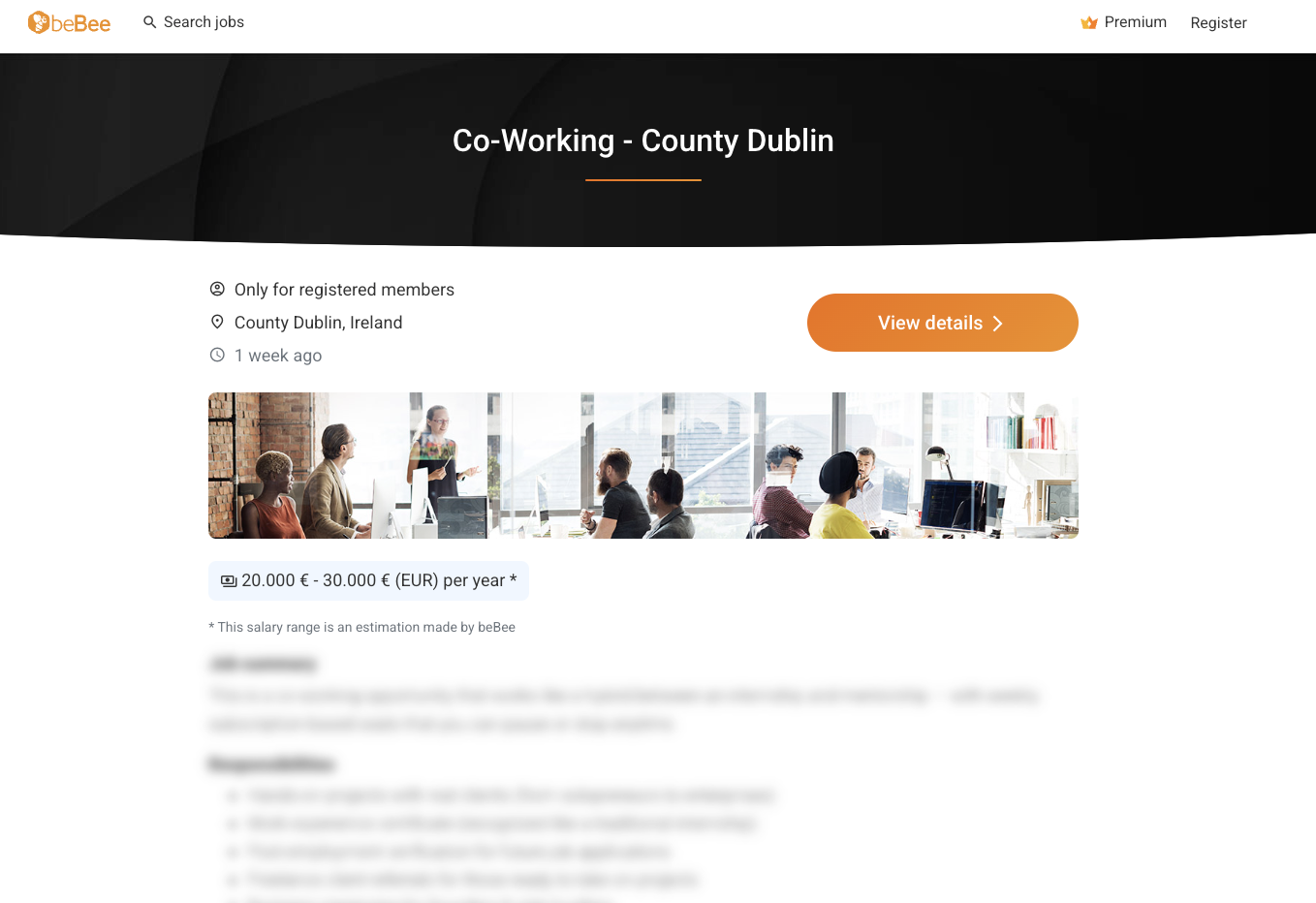
Napblog — our experimental co-working brand built for thinkers and doers — suddenly appeared on three global job boards advertising a position we never created.
The post listed a “Co-Working Job in Dublin” at €20,000–€30,000 per year.
It looked official: a logo, a description, even a location tag.
The only problem? We never posted it.
In reality, the “role” described was a subscription-based co-working program, not a paid job.
Yet multiple aggregator sites — Recruit.net, WhatJobs, and beBee — copied, monetized, and distributed it as a real employment offer.
It was a small misunderstanding with large implications — for startups, creators, and every founder trying to protect their narrative in an AI-driven internet.

🧠 The Anatomy of the Misinformation Loop
What happened to Napblog is not rare.
Modern job boards are powered by automated crawlers — algorithms that scan the web for keywords, titles, and snippets that look like job posts.
When they find something resembling a listing, they “ingest” it into their database and repost it — often without asking.
That’s how the internet ends up with phantom job ads that nobody authorized.
Some even attach AI-generated salary ranges, like the “€20,000–€30,000” on our page, calculated by opaque algorithms trying to estimate a market average.
In our case:
- One platform scraped our co-working program text.
- Another re-published it as a “job” in Ireland.
- A third placed it behind a paywall and charged users €2.99 to “apply.”
A digital whisper became a global echo.
⚙️ Automation Without Accountability
Automation is supposed to save us time.
But when machines act without ethics, they multiply misinformation at scale.
Recruit.net’s own site proudly states:
“We automatically get all the jobs from your website.”
That sentence hides a complex truth: just because data is public doesn’t mean it’s permitted for reuse.
When an algorithm copies your text, logo, and context and republishes it commercially — that’s not “indexing.” That’s unauthorized syndication.
For a small startup, this is more than annoying:
- It confuses applicants who expect a salary that doesn’t exist.
- It misrepresents the brand, suggesting we mislead people.
- It turns honest communication into clickbait, damaging trust.
⚖️ The Legal and Ethical Dimensions
Under EU GDPR (Articles 5 & 6), companies must process data lawfully and transparently.
Re-posting a brand’s information without consent — especially when monetized — can violate both privacy and commercial rights.
Under Irish Advertising Standards Code 4.1, all employment ads must be truthful and not mislead consumers about pay or conditions.
Yet aggregator platforms often operate in a grey area. They claim the content is “publicly available,” but they profit from traffic and subscriptions built on that data.
This isn’t just about one startup — it’s about the blurred line between aggregation and appropriation.
🔍 The Human Impact
Let’s imagine the job seeker scrolling through a feed late at night.
They see “Napblog Co-Working – Dublin – €30,000 per year.”
They feel hope. They pay €2.99 to unlock “Premium Access.”
Then they discover there’s no job — just an unpaid mentorship program designed to build experience.
That’s not harmless noise.
That’s real disappointment, multiplied by thousands of similar listings across the web.
In an age where trust is a currency, misinformation erodes both sides: the employer’s credibility and the candidate’s faith.
🌍 Why This Matters for Every Startup
Startups live and die by reputation.
When your brand narrative gets hijacked by third-party data engines, you lose control of the story.
The Napblog case is a cautionary tale for every founder who:
- Lists internships, co-working programs, or learning seats online
- Uses open job schemas or public Notion pages
- Relies on multiple hiring platforms without centralized oversight
If your content looks like a job, aggregators will treat it as one.
And once it’s scraped, it’s almost impossible to stop the chain reaction.
💬 The Irony of “AI” Without Intelligence
At Napblog, we celebrate AI — responsibly.
We use machine learning to augment human creativity, not replace integrity.
What we’re witnessing in the job-aggregator ecosystem is automation without awareness — a system that scrapes, re-labels, and re-monetizes without context.
It’s the digital version of gossip: algorithms passing along half-truths until the origin is unrecognizable.
🧩 Lessons Learned — and Shared
From this experience, Napblog developed a small playbook for startups and co-working communities:
1. Monitor your brand proactively
Set up Google Alerts for your company name + “job” or “career.”
This simple step helps catch unauthorized listings fast.
2. Use a robots.txt file
Block known job-board crawlers from scraping your site.
Example:
User-agent: RecruitBot
Disallow: /
User-agent: WhatJobsBot
Disallow: /
3. Publish clear disclaimers
If you run unpaid or subscription-based programs, clearly label them as non-employment opportunities.
4. Document everything
Take screenshots, save URLs, and send formal GDPR takedown requests.
Most platforms comply once they see legal language.
5. Educate your community
Explain to followers that if a job looks suspicious, always confirm via the company’s official website or LinkedIn page.
🧭 Beyond Napblog: The Larger Narrative
This isn’t just about job boards.
It’s about AI’s growing influence over public perception.
From search results to social feeds, automated systems shape what people believe about a brand — even when the brand never said it.
That’s the paradox of the digital age: the more data we share, the less control we have over its meaning.
Napblog’s philosophy — “Sleep with the problem, wake up with the solution” — applies here too.
When misinformation spreads faster than truth, we need to pause, reflect, and rebuild systems that value context as much as content.
🛡️ Reclaiming Digital Ownership
After weeks of investigation, we sent formal notices to Recruit.net, WhatJobs, and beBee.
Each was asked to remove the listing, identify the data source, and prevent further syndication.
Whether they respond or not, this incident sparked a deeper mission inside Napblog:
To help startups own their digital narrative — from content to reputation.
Because innovation isn’t just about building new tools.
It’s about ensuring the tools we already have don’t distort the truth we stand for.
🌱 Closing Thoughts: Building an Honest Internet
Napblog was founded as a space where creativity meets clarity.
We believe innovation should never come at the cost of integrity.
If AI can generate misinformation, it can also generate accountability — through transparency logs, verified data sources, and smarter ethics layers in aggregation systems.
The future of digital trust will belong to brands that protect their voice as fiercely as they pursue their vision.
And sometimes, it takes one false job ad to remind us why authentic communication is our greatest startup asset.
✍️ Call to Action
If you’re a founder, marketer, or job seeker who’s faced a similar issue, share your story.
Let’s build a collective awareness around AI aggregation ethics.
Because until we redesign these systems, truth will always need human curators — not just algorithms.
At Napblog, we’re still co-working, still learning, and still believing that every breakthrough starts with a pause.



